
AlphaOne是什么?
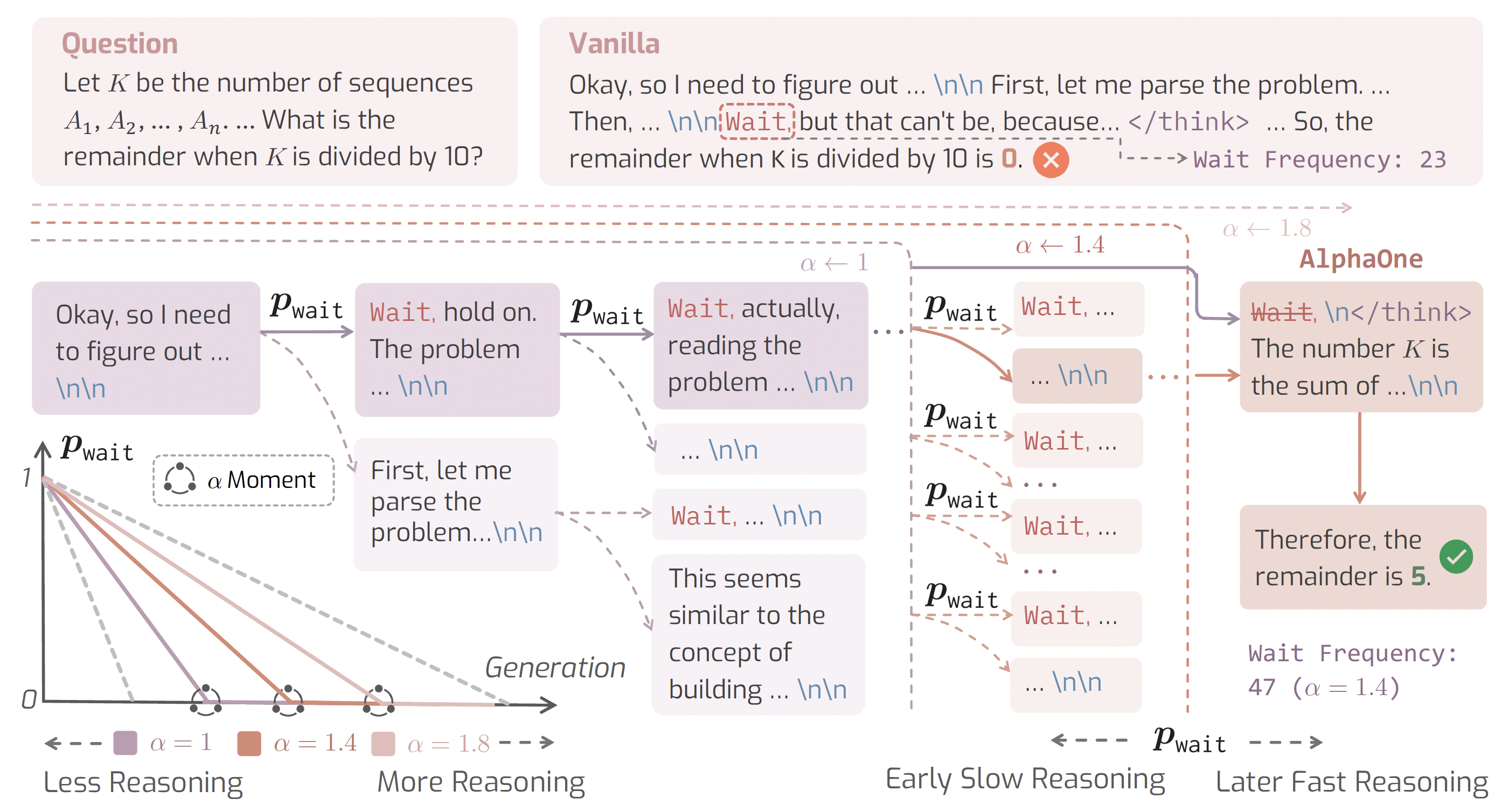
AlphaOne(α1)是一种调节大型推理模型(LRMs)在测试时思维进度的通用框架。通过引入 α 时刻和动态安排慢速思维转变,α1 实现了慢速到快速推理的灵活调节。这一方法统一并推广了现有的单调缩放方法,优化了推理能力与计算效率。该产品适用于需要处理复杂推理任务的科研人员和开发者。
产品特色
引入 α 时刻,动态调整思维阶段。
通过伯努利随机过程调节慢速思维的转变。
利用思考结束标记终止慢思维,促进快速推理。
支持多种数学和科学基准测试的评估。
提供灵活的评估脚本,便于模型评估和监控。
应用场景
用于数学竞赛问题的解答评估。
支持科学研究中的推理任务。
可在代码生成与执行中应用。
适用人群
本产品适合科研人员和开发者,特别是那些需要解决复杂推理任务或开发智能应用的人群。其灵活的思维调节机制能够提高模型在复杂任务中的表现。
使用指南
创建并激活 AlphaOne 的 conda 环境。
安装所需的依赖包。
运行评估脚本以测试模型。
监控运行进度以获取实时反馈。
根据需要调整模型参数以优化结果。
 蘑菇导航
蘑菇导航
评论区
我要评论
评论列表