
BitNet b1.58 2B4T是什么?
BitNet b1.58 2B4T是微软研究团队推出了一款开源大型语言模型,拥有20亿参数,能在普通CPU如苹果M2上高效运行。BitNet b1.58 2B4T模型以仅-1、0、1的极简权重实现高内存和计算效率,在多个推理任务中超越Meta、谷歌等同类模型,速度更快、资源占用更低。惟一限制是需依赖微软自研框架bitnet.cpp,兼容性仍受限。
主要功能
语言理解:经过在包含 4 万亿标记的语料库上训练,能理解各种自然语言文本,涵盖不同领域和主题,可准确把握文本语义、情感等多方面信息。
数学推理:在 GSM8K 等数学基准测试中表现优异,可处理各类数学问题,包括简单运算、复杂应用题及数学逻辑推理等。
编码能力:对代码相关任务有良好处理能力,能进行代码生成、代码纠错、代码理解等工作,支持多种编程语言。
对话能力:通过多阶段训练,尤其是采用直接偏好优化(DPO)方法利用相关数据集提升了对话能力,可与用户进行自然、流畅的对话,回答问题、提供建议、进行讨论等。
技术原理
低精度架构:以 1.58 位低精度架构原生训练,摒弃传统 16 位数值,采用定制 BitLinear 层,将权重限制为 - 1、0、+1 三种状态,形成三值系统,每权重仅需约 1.58 位信息存储,大幅减少内存占用。
量化策略:层间激活值以 8 位整数量化,形成 W1.58A8 配置,既降低数据精度又保证模型性能,减少计算量和能耗。
架构调整:调整 Transformer 架构,引入平方 ReLU 激活函数,能更好处理非线性问题,提高模型表达能力;采用标准旋转位置嵌入(RoPE),有效捕捉文本中的位置信息,提升语言理解准确性;使用 subln
归一化,增强模型训练稳定性,确保低位训练有效进行。
应用场景
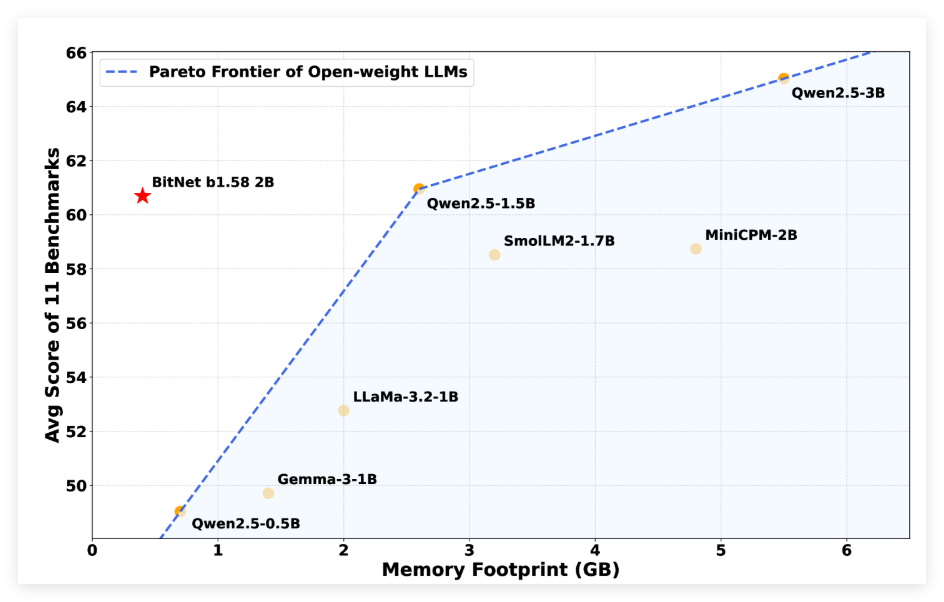
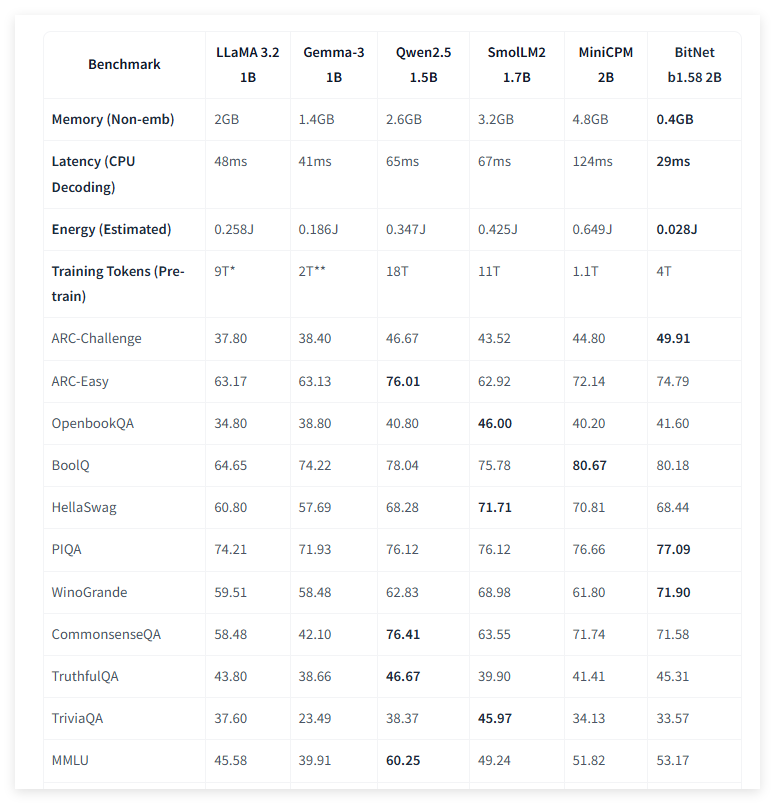
资源受限设备:非嵌入内存占用仅 0.4GB,能耗低至每 token 0.028 焦耳,适合部署在移动设备、物联网设备和边缘计算设备等资源受限环境,为用户提供语言服务,如智能语音助手、文本翻译等。
实时交互应用:CPU 解码延迟仅 29 毫秒,推理速度快,可应用于实时对话系统、在线智能客服等场景,能快速响应用户输入,实现流畅实时交互。
科研与开发:以 MIT 许可证在 Hugging Face 发布,为研究人员和开发者提供开源模型,便于开展自然语言处理相关研究实验,推动人工智能技术发展,也可作为基础模型进一步微调优化,开发特定领域应用,如医疗、金融领域的智能问答系统和信息分析工具等。
 蘑菇导航
蘑菇导航
评论区
我要评论
评论列表