
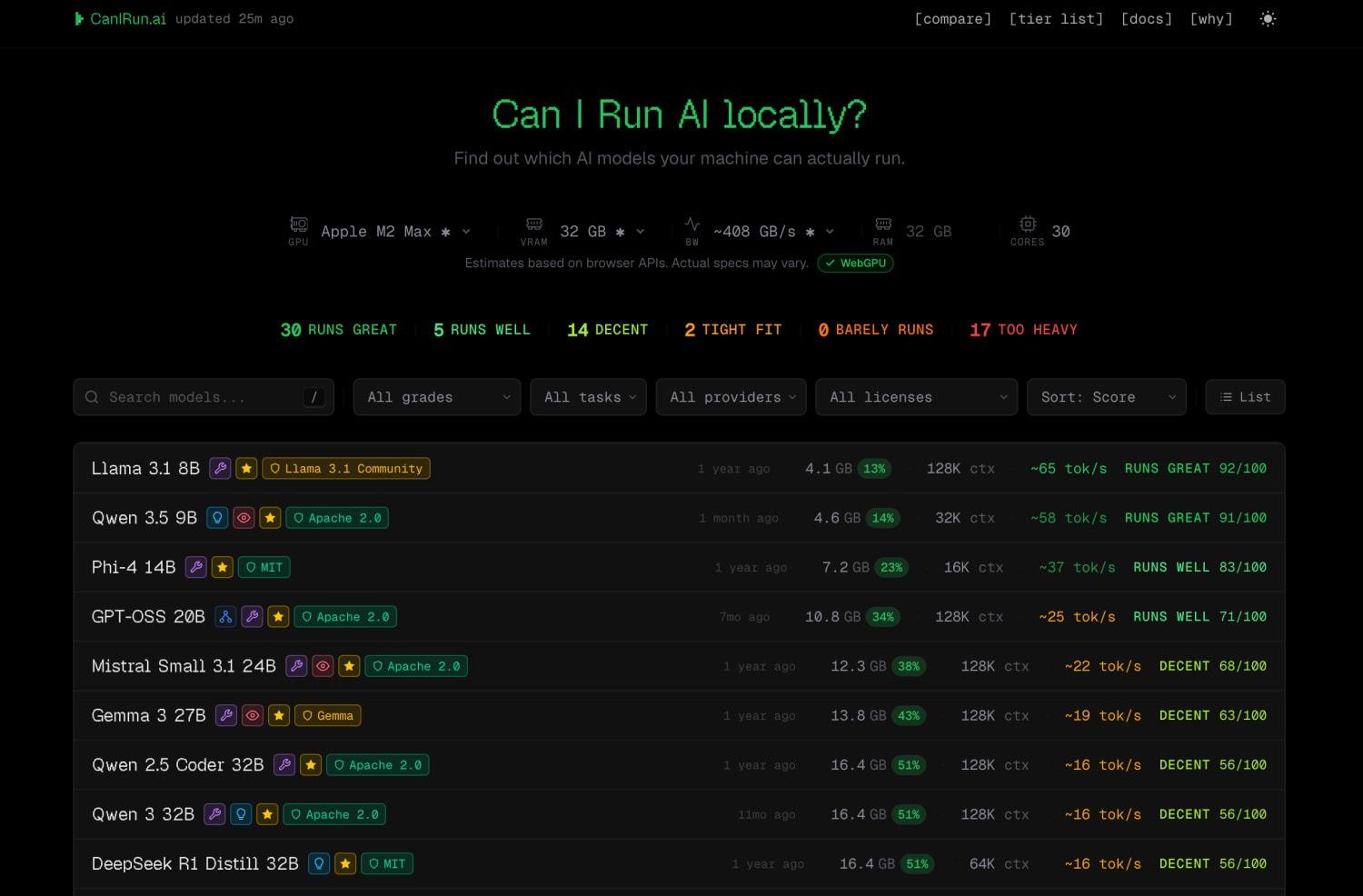
CanIRun.ai是什么?
CanIRun.AI是一个专门为本地运行大模型(LLM)而生的“硬件-模型兼容性检测工具”,帮你避免下载了模型却跑不动的尴尬。
工作流程
根据网站界面,它的检测流程融合了“自动检测”与“手动选择”,非常直接:
自动识别硬件:你打开网站后,它会通过浏览器API自动读取你电脑的关键配置,主要是显卡(GPU)型号和显存(VRAM)大小,这是运行大模型最关键的瓶颈。
浏览或筛选模型:网站内置了一个包含上百个主流模型(Llama, Qwen, DeepSeek, Gemma等)的数据库。你可以按模型名称、参数规模(如7B, 70B)、所需显存等条件进行筛选。
查看兼容性评估:对于每个模型,网站会根据你的硬件,直观地给出从“Runs great (运行极佳)”到“Too heavy (负担太重)”的6档评估结果,并清晰显示模型运行所需的显存。
最适合这三类人
本地AI玩家与发烧友:想第一时间体验最新开源模型(如刚发布的Llama 4),但不确定自己的“战斗机器”是否扛得住。先上CanIRun查一下,避免浪费时间下载巨型文件。
注重隐私与成本的开发/企业团队:计划进行本地化部署以保护数据安全、节省API开销。可以用此工具快速评估现有服务器或工作站资源,为采购或模型选型提供参考。
跃跃欲试的新手小白:手头有一台还不错的PC或Mac,想试试本地跑AI,但完全没概念。这个工具能给你最直观的指导:你的电脑到底能玩哪种“体量”的模型。
CanIRun使用技巧
关注“量化版本”:网站上的模型大小(如“4.6 GB”)通常是4-bit或8-bit量化后的版本。量化是一种模型压缩技术,能显著降低显存需求。同模型,更低量化(如Q4)跑得更快,但可能轻微影响效果。
区分“运行”与“流畅运行”:“Tight fit (勉强能跑)”表示模型刚好能塞进显存,但生成速度可能极慢或系统不稳定。建议寻找评估结果为“Runs well (运行良好)”或以上的模型。
CPU+RAM是备选方案:如果你的显卡显存不足,但拥有大容量系统内存(RAM)和较新的CPU,网站评估时也可能提示你可以纯用CPU运行。这速度会慢很多,但“能跑”是第一步。
它的评估依据是?
网站核心依据是模型加载所需的最低内存/显存。通用估算公式是:
所需显存(GB) ≈ 模型参数量(十亿) × (量化位数 / 8)
7B模型,4-bit量化 → 7 × (4/8) ≈ 3.5 GB 显存
70B模型,4-bit量化 → 70 × 0.5 ≈ 35 GB 显存
CanIRun 就是拿你的硬件数据,去和每个模型按此方法计算出的数值进行比对。其数据主要基于常见的推理框架(如llama.cpp, Ollama)和社区公认的经验值。
小编提醒
CanIRun提供的是快速、可靠的估算参考,而非绝对保证。实际性能还会受模型推理软件(如Ollama, LM Studio)、操作系统、后台任务以及上下文长度(你与模型对话的长度)的影响。所以,把它当作一个非常棒的“筛选漏斗”和“预检工具”就对了。
 蘑菇导航
蘑菇导航
评论区
我要评论
评论列表