


FastVLM是什么?
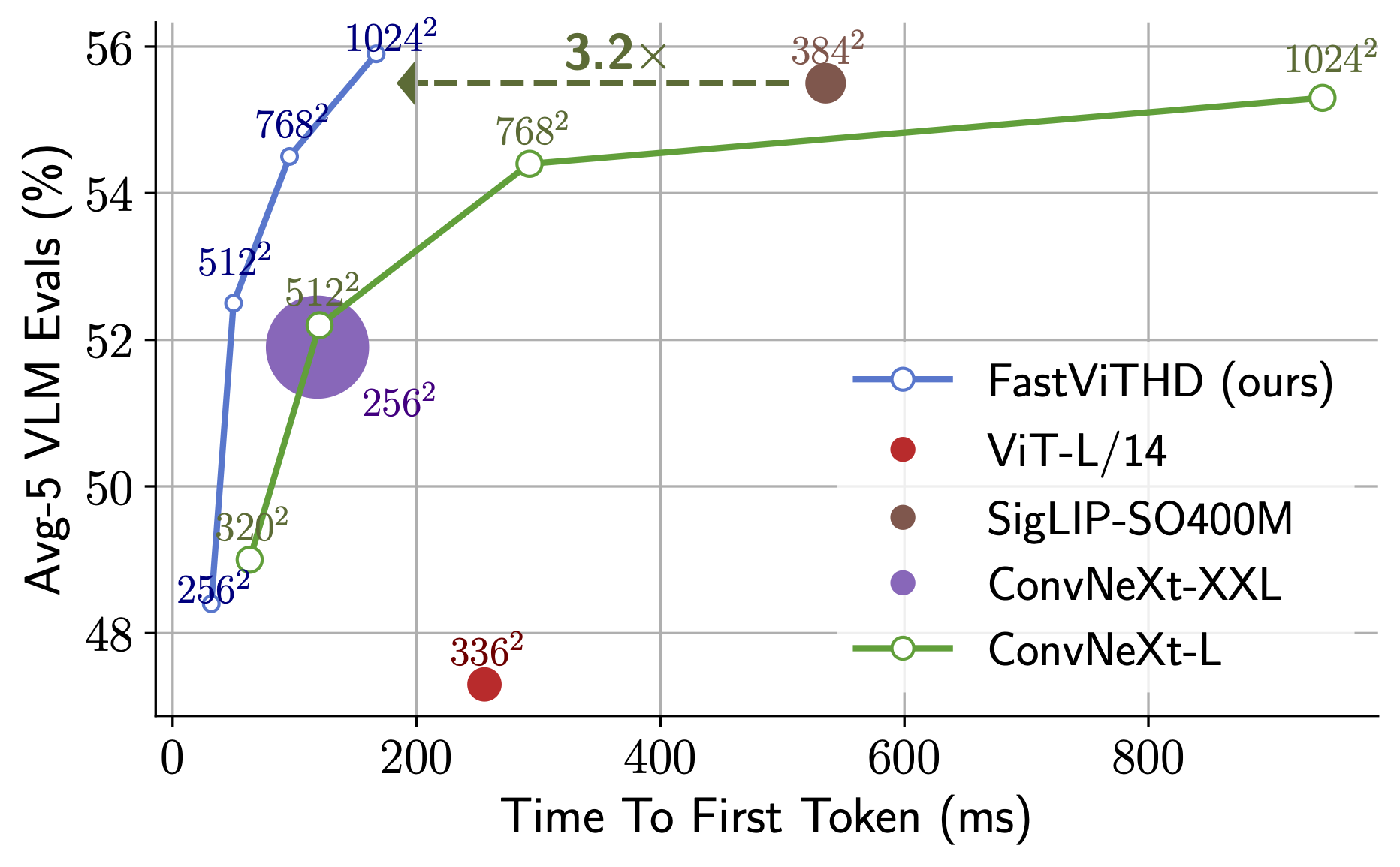
FastVLM 是苹果公司推出的一种高效的视觉编码模型,专为视觉语言模型设计。它通过创新的 FastViTHD 混合视觉编码器,减少了高分辨率图像的编码时间和输出的 token 数量,使得模型在速度和精度上表现出色。FastVLM 的主要定位是为开发者提供强大的视觉语言处理能力,适用于各种应用场景,尤其在需要快速响应的移动设备上表现优异。
产品特色
FastViTHD 混合视觉编码器:有效减少 token 输出,提升编码效率。
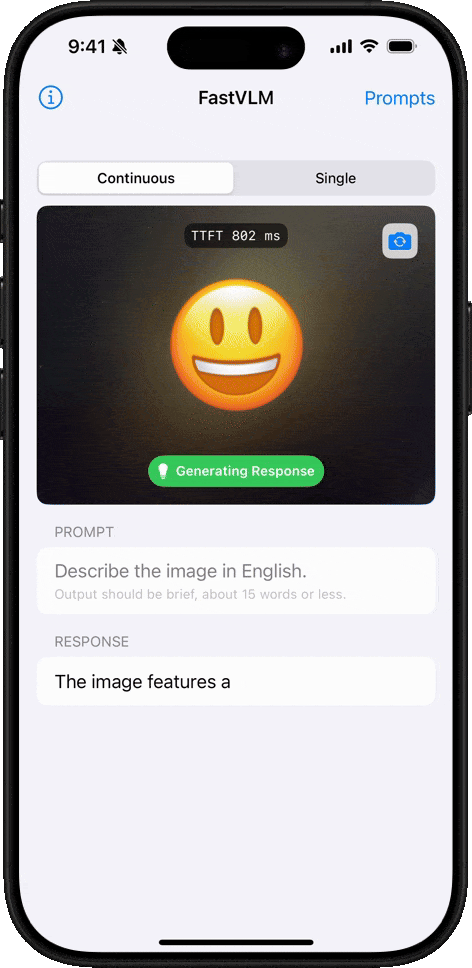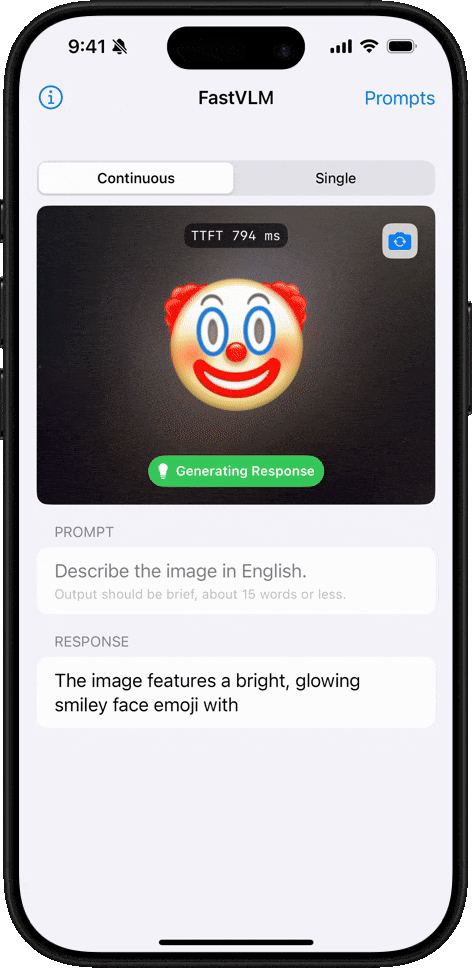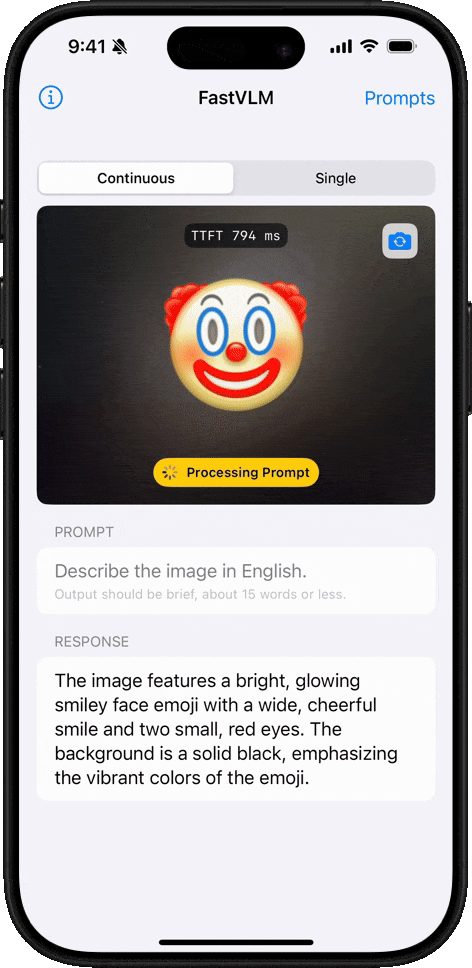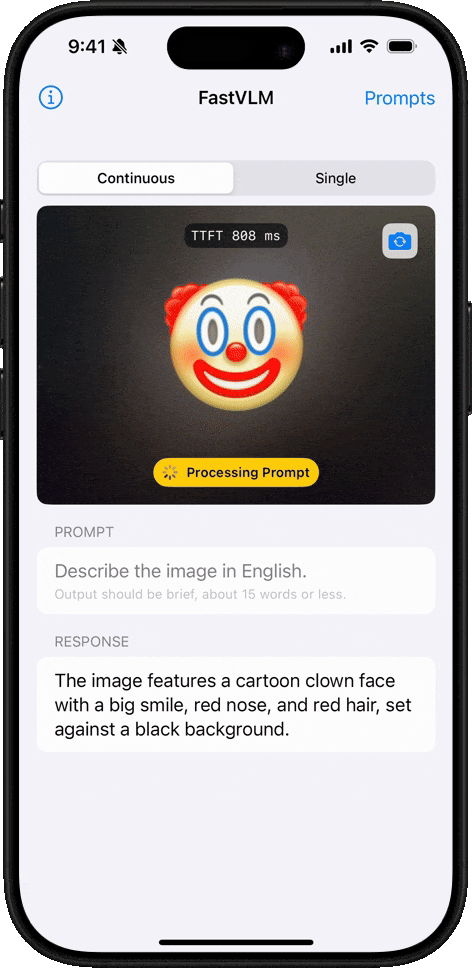
显著缩短 Time-to-First-Token(TTFT),提高用户体验。
支持多个变体,适应不同应用需求和硬件配置。
提供移动设备兼容的推理能力,拓展使用场景。
包含详细的使用说明和模型导出工具,便于开发者集成。
应用场景
在移动应用中快速识别和描述图像内容。
用于实时的图像和文本交互功能,如智能客服。
在教育软件中实现图像理解与语言描述的结合。
适用人群
该产品适合从事人工智能、计算机视觉和自然语言处理的研究人员和开发者,尤其是希望在移动端实现高效图像和文本交互的用户。FastVLM 的高效性和灵活性使其成为快速迭代开发的理想选择。
使用指南
克隆或下载 FastVLM 代码库。
安装依赖项并创建 conda 环境。
下载预训练模型检查点。
运行推理脚本,输入图像和提示信息。
查看并分析模型输出的结果。
 蘑菇导航
蘑菇导航
评论区
我要评论
评论列表